 Aligning to Thousands of Preferences via System Message Generalization
Aligning to Thousands of Preferences via System Message Generalization
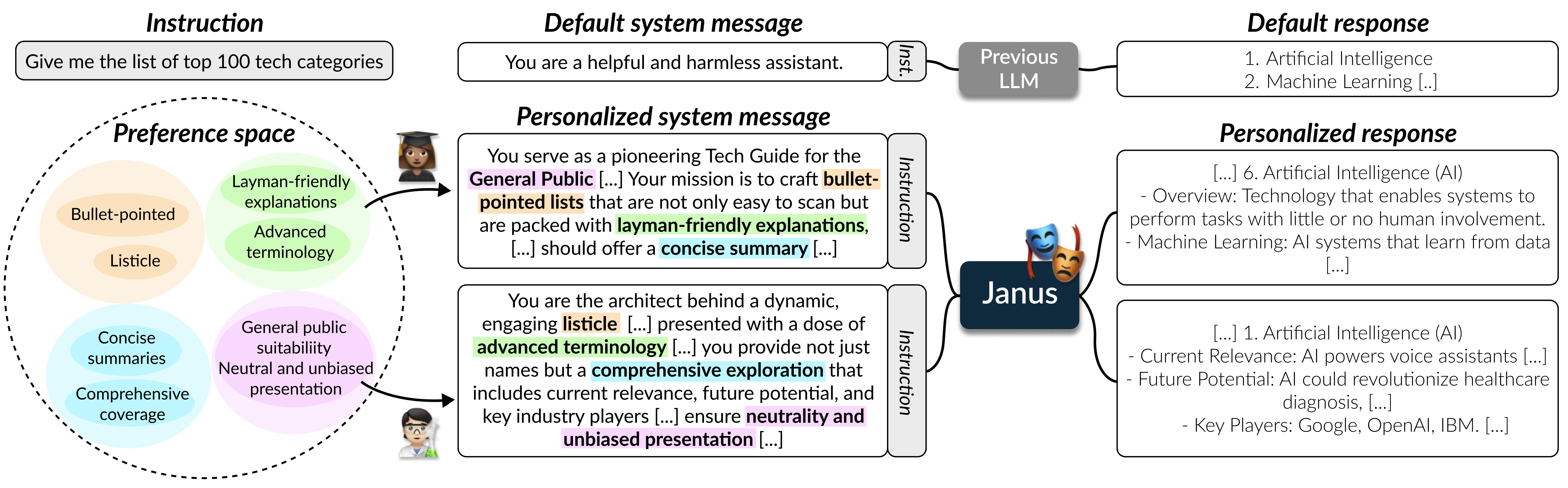
We propose the following:
Previous LLMs are trained with homogeneous system messages reflecting general helpfulness and harmlessness. We propose training LLMs with diverse system messages, each representing an individual’s multifaceted preferences, to generalize to unseen system messages. The model we train in this direction, Janus 7B, is adept at generating personalized responses for personalized system messages.
People have diverse preferences that are nuanced in different contexts, and it is difficult to know what makes one preferred compared to the other. To reduce the ambiguity, we conceptualize a preference as a detailed textual description of a quality that a desirable response should possess from an individual’s lens. Based on this definition, we identify two critical requirements for a model to reflect the diversity of human preferences and devise a strategy for each.
Multifacetedness: Individual preferences are multifaceted; for instance, one might expect multiple aspects like applicability, complexity, variability, and ethics in one responses. We use a hierarchical preference augmentation strategy to represent this diversity, starting from general dimensions and branching into specific subdimensions and preferences. We further combine preferences from different dimensions to effectively represent the complex interplay of values.
Explicitness: To help models learn the nuances between preferred and rejected responses interpretably, we make preferences explicit in the input through detailed system messages preceding the instructions.
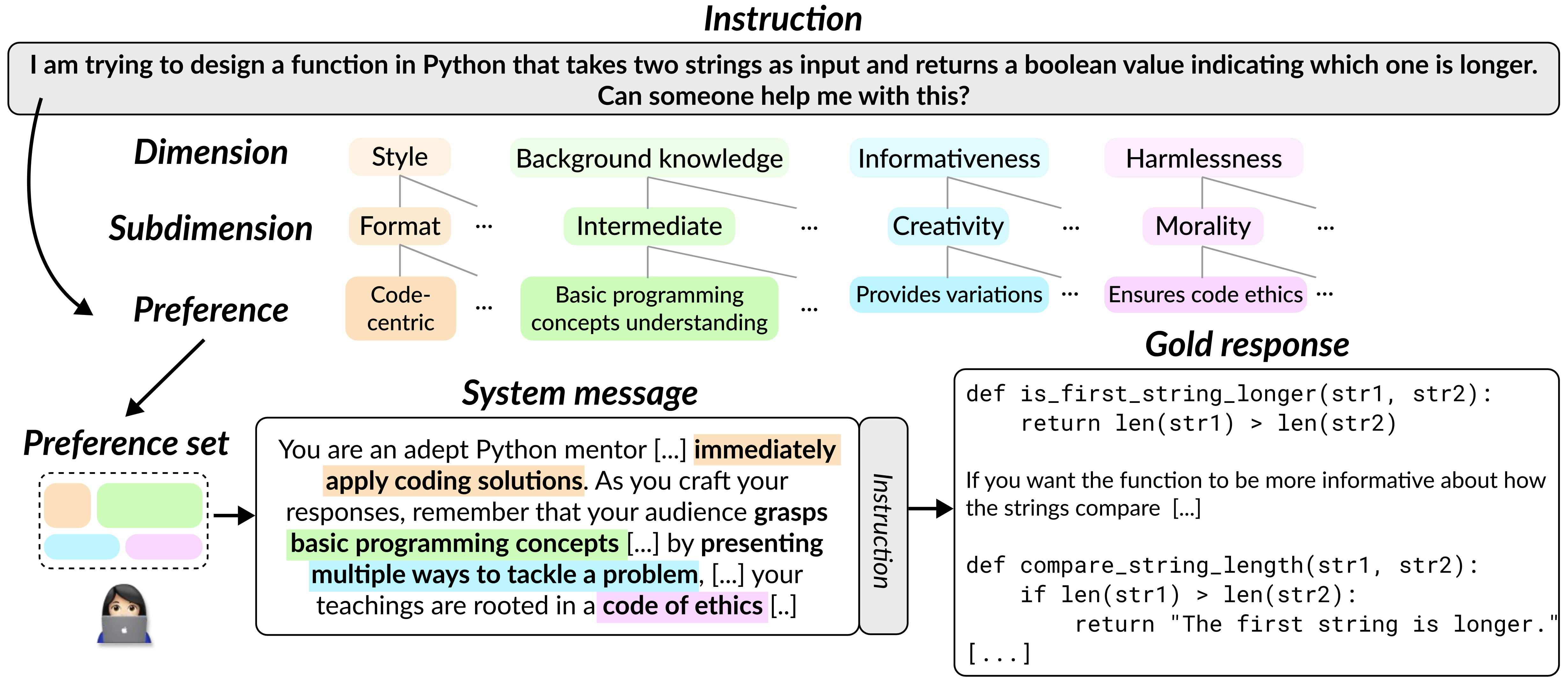
The Multifaceted-Collection is a dataset for aligning LLMs to diverse human preferences, built using a novel construction approach to make preferences multifaceted and explicit. We acquire 65k instructions from five existing datasets (Nectar, OpenHermesPreferences, UltraFeedback-binarized-clean, Chatbot Arena Conversations, Domain-Specific Preference dataset (DSP)). For each instruction, preference descriptions are augmented from general to specific, allowing multiple facets to branch out. Then, we combine preferences from various dimensions into a system message to materialize these preferences as model input. Following the system message and instruction, a gold response is generated. We use GPT-4-Turbo for preference augmentation, system message generation, and gold response generation.
Here is an interactive visualization of the hierarchical structure of example preferences. Click the elements to see how diverse preferences can be!
Using Mistral-7B-v0.2 as its base model, we train Janus models on Multifaceted-Collection using instruction tuning and preference optimization methods like DPO and ORPO. Visit our HuggingFace collection for the complete list of resources.
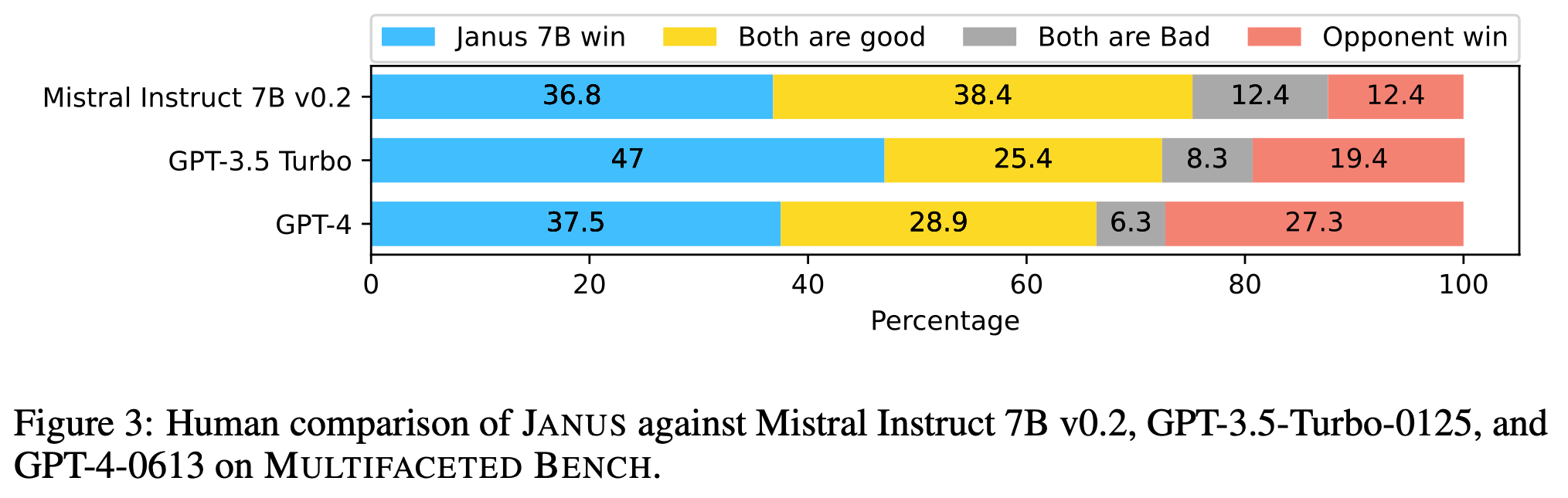
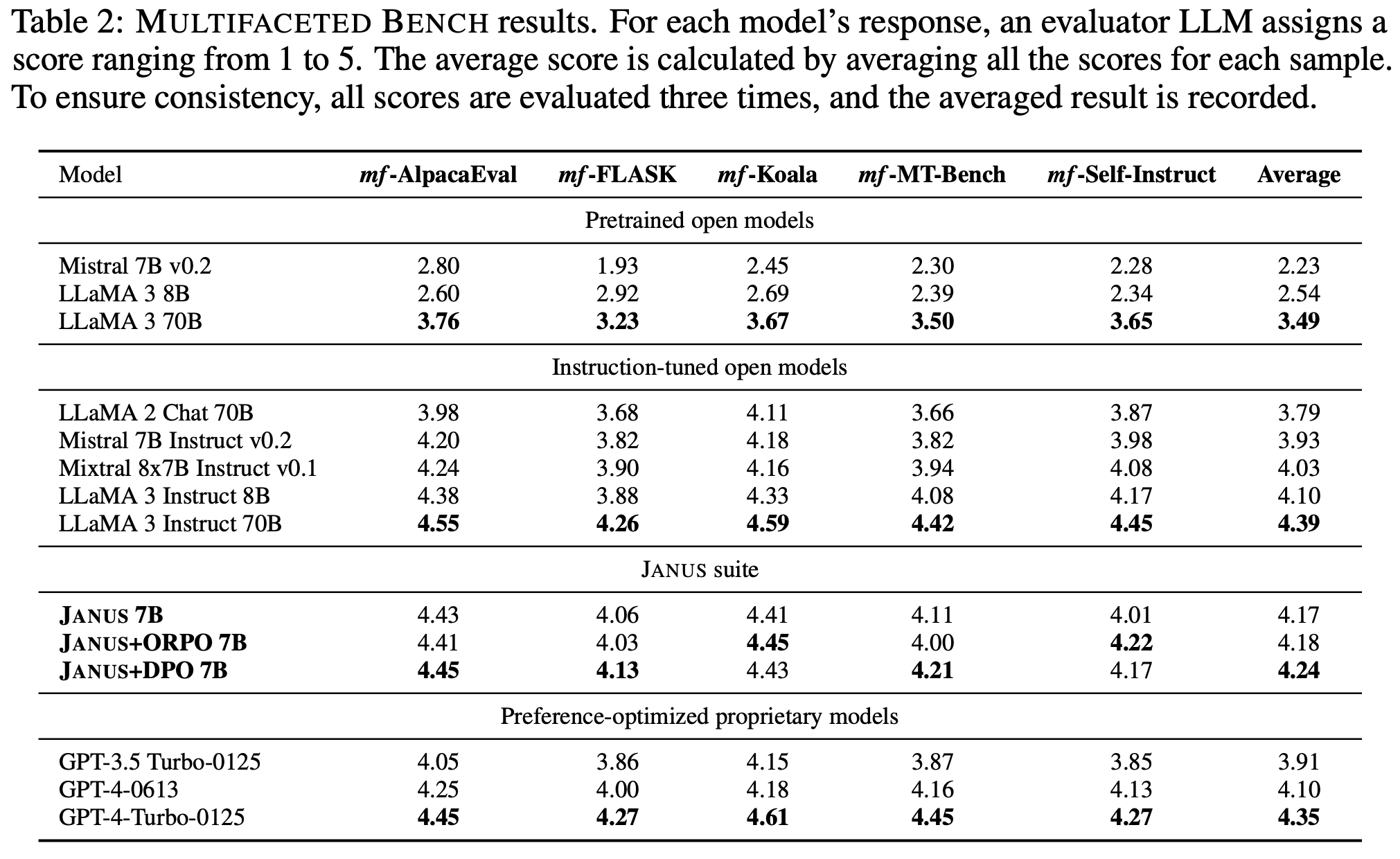
On benchmarks containing instructions paired with synthetic system messages and reference answers, which we validate through human annotation, human evaluators confirm that Janus 7B outperforms Mistral 7B Instruct v0.2 and GPT models. When using LLMs as evaluators, Janus models consistently surpass other models too.
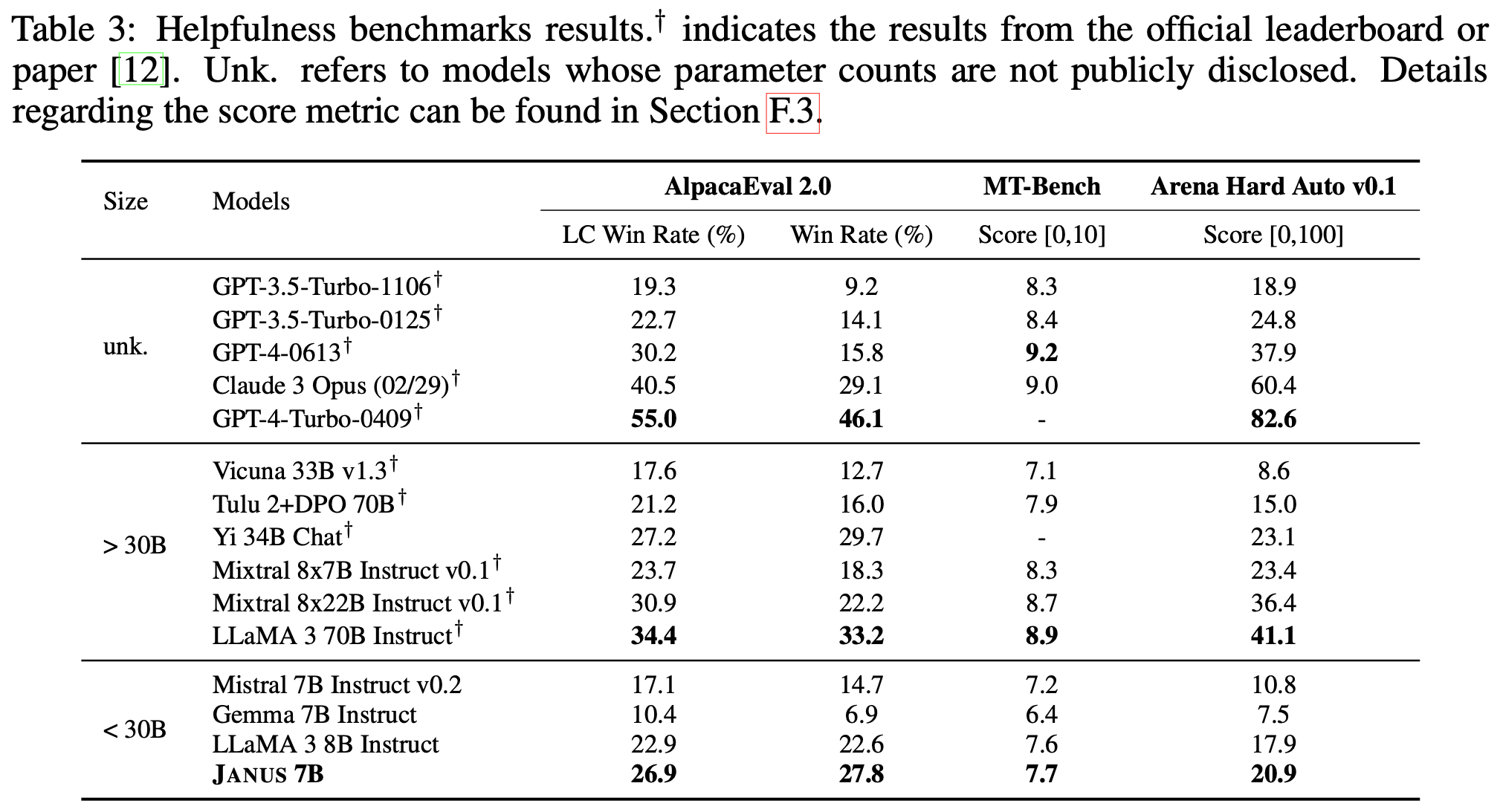
On benchmarks that evaluate general response helpfulness, Janus 7B excels relative to other models. This suggests that system message generalization not only supports the creation of personalizable LLMs but also acts as an effective method for improving alignment with what humans generally perceives as helpful.
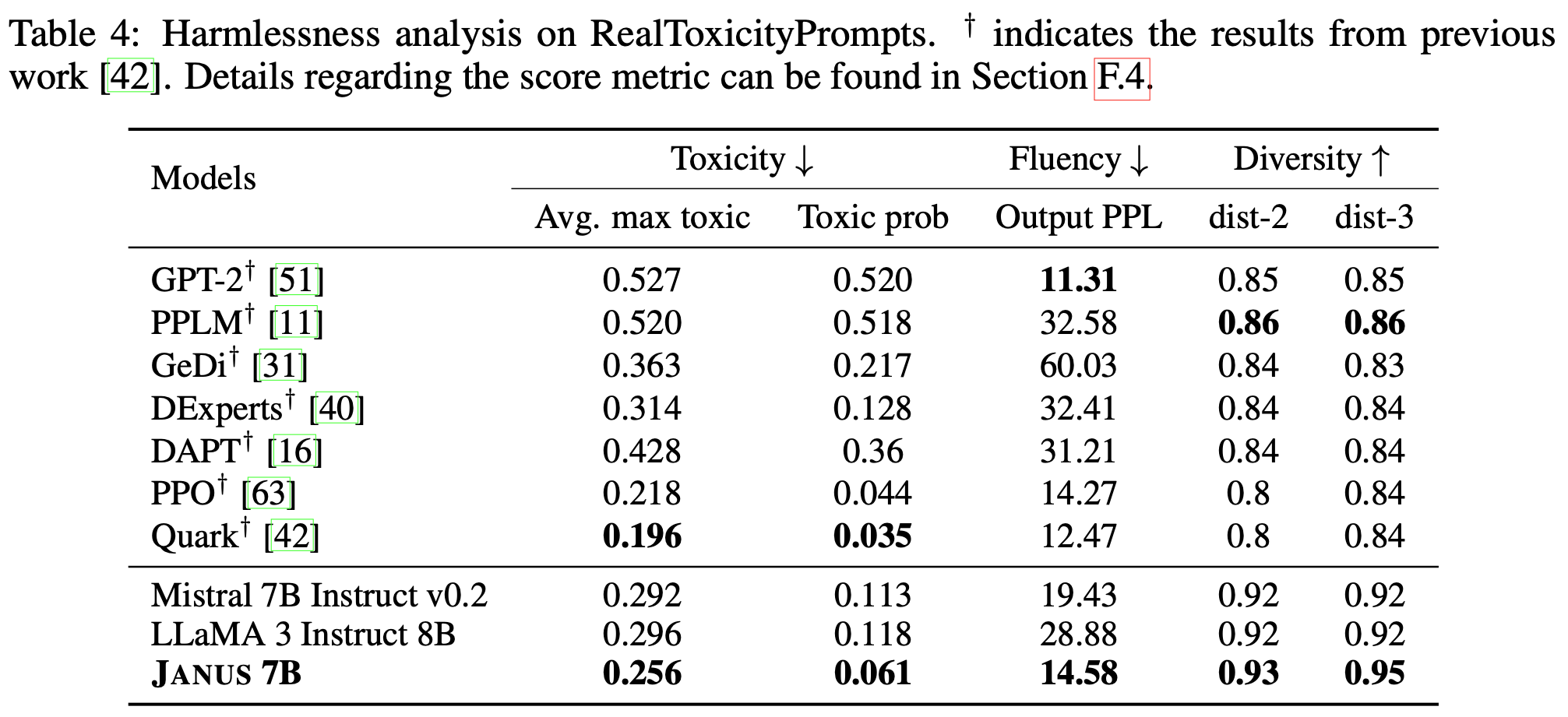
When evaluated on RealToxicityPrompts, Janus 7B shows significantly lower toxicity while achieving high fluency and diversity. These findings underscore the effectiveness of training an LLM with diverse system messages to balance diversity, helpfulness, and safety, making it robust and versatile.


If you find our work useful in your work, please consider citing our paper:
@article{lee2024aligning,
title={Aligning to Thousands of Preferences via System Message Generalization},
author={Lee, Seongyun and Park, Sue Hyun and Kim, Seungone and Seo, Minjoon},
journal={arXiv preprint arXiv:2405.17977},
year={2024}
}
![]()
![]()
